

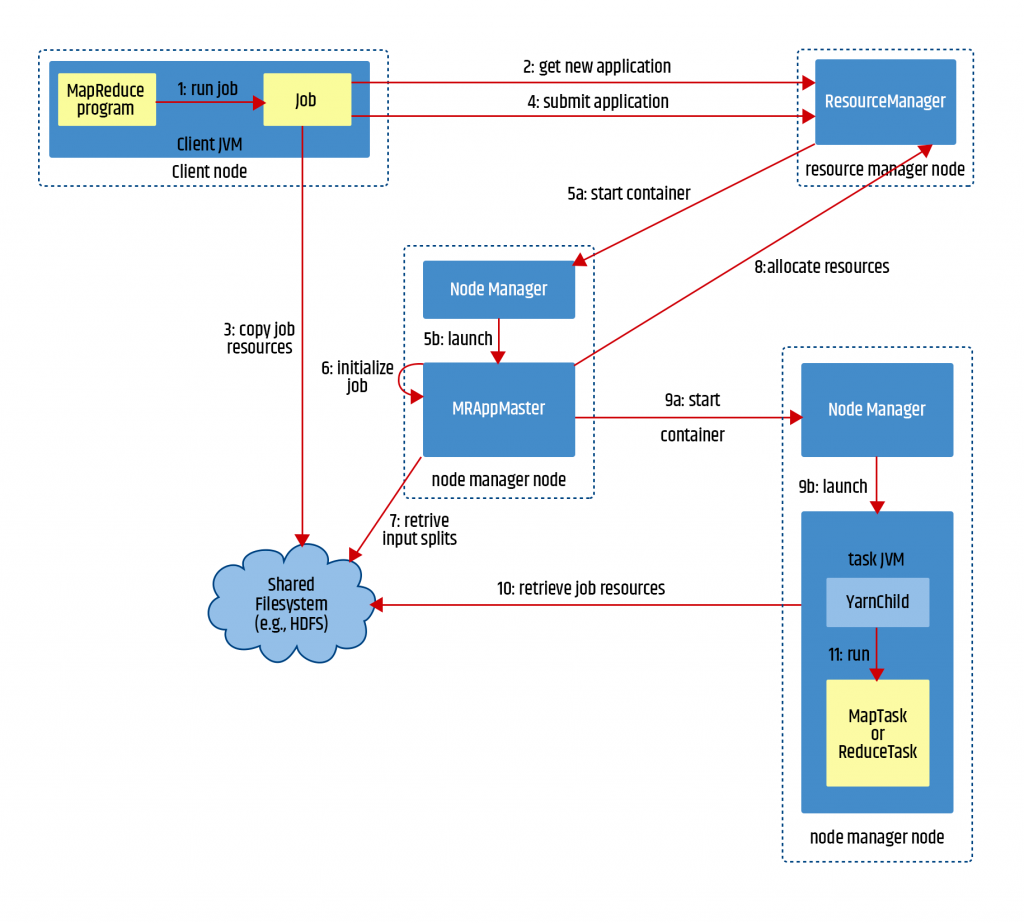
Now let us talk about Map Reduce Job Execution Life Cycle. While YARN is Resource Management framework, Map Reduce is distributed data processing framework.
On Gateway Node we can submit map reduce jobs using hadoop jar command.
https://gist.github.com/dgadiraju/0d3df07693e78d07164af0c14493707d
- There will be JVM launched on the gateway node.
- It will talk to Resource Manager and get YARN Application id as well as Map Reduce Job id.
- Also, client will copy the job resources into HDFS using higher replication factor. Job resources are nothing but jar file used to build the application along with dependent jars, additional data files that are passed at run time etc.
- Resource Manager will choose one of the servers on which node manager is running and create a container. It is called as YARN Application Master.
- In Map Reduce, YARN Application Master will take care of managing the life cycle of the job.
- Talk to the Node Manager and create containers to run Map Tasks as well as Reduce Tasks to process the data.
- Fault Tolerance of tasks – If any task fails, it will be retried (four times) on some other node and reprocess the data. If any task fails more than four times then the entire job will be marked as failed.
- Also if Node Manager is down, then all the running tasks on that node will be retried on other nodes.
- Fault Tolerance of application master – If the application master is failed, it will be recreated on some other node and entire job will be rerun.
- Speculative Execution – If there is any task running slow compared to others, there will be another attempt of the same task on some other node to process the same data (same split). Whichever attempt is finished first will be completed and all other attempts will be killed.
- All Map Tasks and Reduce Tasks collect metrics as they process data, Application Master will consolidate that information and send periodically to the client.
- You can review the source code of wordcount program here.
- First Map Tasks will be created as YARN Containers, job resources will be copied on to the Task and map logic will be executed.
- As Map Tasks (80% of them) are completed, Reduce Tasks will also be started as YARN Containers and reduce logic will be executed.
- This process of taking logic to the data is called Data Locality. In conventional applications code will be deployed in application server and data has to be copied to the application server for processing.
- Data Locality is significant performance booster for heavy weight batch processing.
- As Map Tasks and Reduce Tasks complete processing of data assigned to them, they will be garbage collected.
- Once the job is completed, Application Master will be garbage collected after copying the log files to HDFS.
- We can get the logs of completed Map Reduce jobs using job history server.
By this time you should have set up Cloudera Manager, then install Cloudera Distribution of Hadoop, Configure services such as Zookeeper, HDFS, and YARN. Also, you should be comfortable with HDFS Commands as well as submitting jobs.
Make sure to stop services in Cloudera Manager and also shut down servers provisioned from GCP or AWS to leverage credits or control costs.