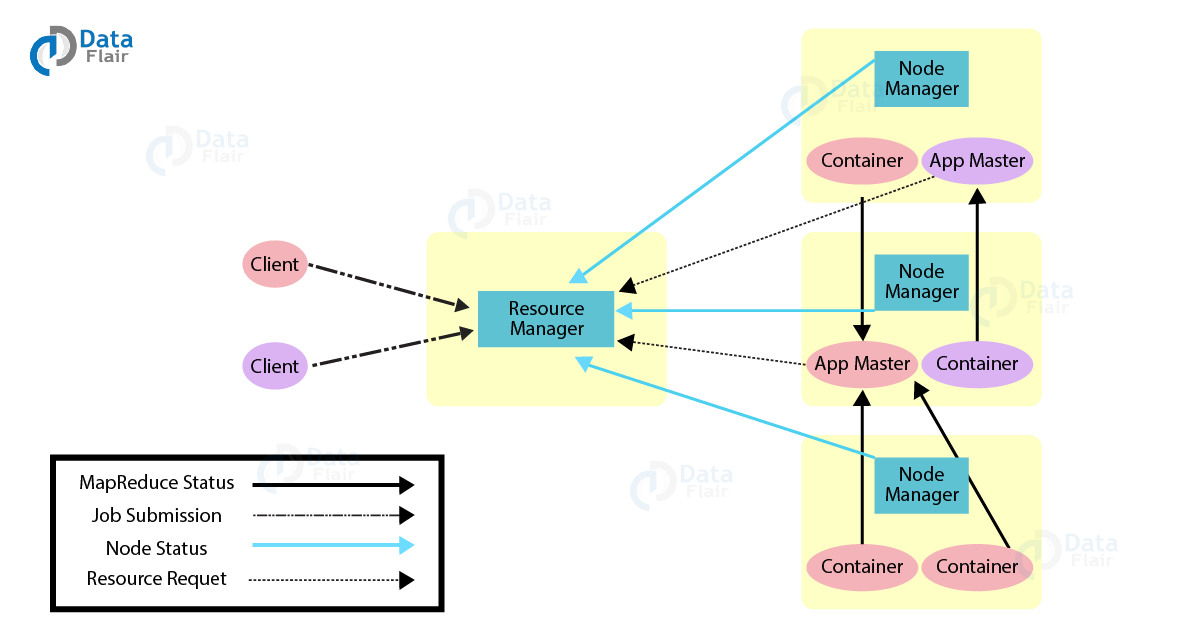
YARN (Yet Another Resource Negotiator) is a resource management layer in Apache Hadoop that enables the processing of large datasets across a cluster of computers. It separates the job scheduling and resource management functions that were previously combined in Hadoop MapReduce, allowing for more flexibility and scalability in distributed computing.
MapReduce is a programming model for processing large datasets in parallel across a cluster of computers. It consists of two main functions: Map and Reduce. The Map function takes in input data and outputs a set of key-value pairs, while the Reduce function takes in the key-value pairs and produces a set of output data.
In YARN-based MapReduce, the MapReduce job is split into several tasks that are executed across the cluster. YARN handles the allocation of resources for each task and monitors their progress. The MapReduce framework takes care of processing the data within each task, using the Map and Reduce functions.
YARN-based MapReduce allows for efficient processing of large datasets across a cluster of computers, making it a popular choice for big data processing in industries such as finance, healthcare, and e-commerce.