

Now let us explore different components related to HDFS and how they are used to store files in HDFS.
- We need to configure the Namenode, Secondary Namenode, Datanodes and balancer etc as part of HDFS. Here Namenode act as master and Secondary Namenode as helper for Namenode where as Datanodes act as slaves.
- Actual data will be stored in Datanodes in the form of blocks while metadata is stored in Namenode’s heap (memory)
- Click here for a nice article which explains details with respect to directory structure on datanode data directories.
- Here is the pictorial representation about how HDFS stores, reads and writes files.
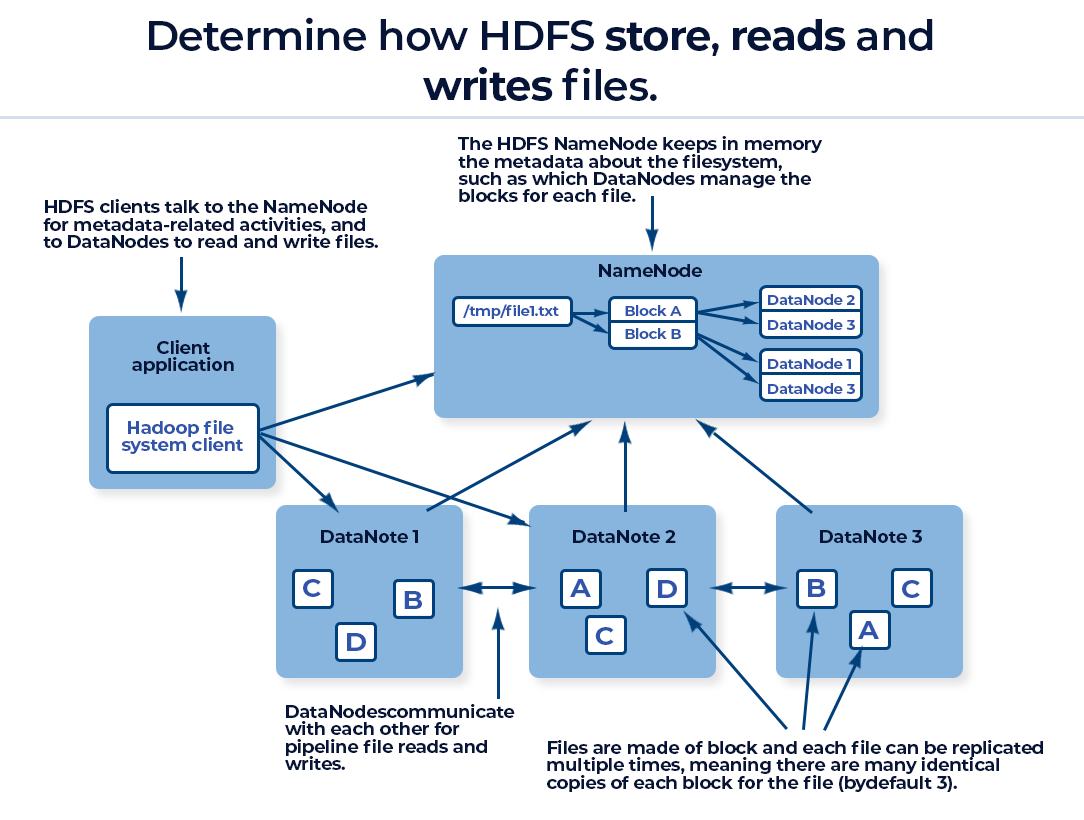
- HDFS uses checksum to ensure data integrity of the files. Client will compute checksum for each block and matches with the checksum returned by Datanodes after copying the blocks on to them.
- Metadata is logged into edit logs and also periodic snapshot known as fsimage is built by merging edit logs into fsimage.
- Changes to metadata is also logged into edit logs under directory defined as part of dfs.name.dir. If there are no edit logs then we will not be able to recover metadata if Namenode crashes as memory is transient.
- These edit logs are periodically merged into fsimage so that Namenode metadata can be recovered faster.
- This process of merging edit logs into last fsimage and creating new fsimage is called as checkpointing (Secondary Namenode takes care of checkpointing)
- We will get into details of edit logs and fsimage, and how they are used for recovering metadata at a later point in time.
- Datanodes send heartbeat to Namenode at frequent and regular intervals. As part of the heartbeat, additional information about available storage will be sent to Namenode. Also periodically block report from each Datanode is sent to Namenode.
- A balancer is a service which keeps track of data nodes to distribute data appropriately across all the nodes.
- Namenode Web Interface : http://<namenode-server>:50070