

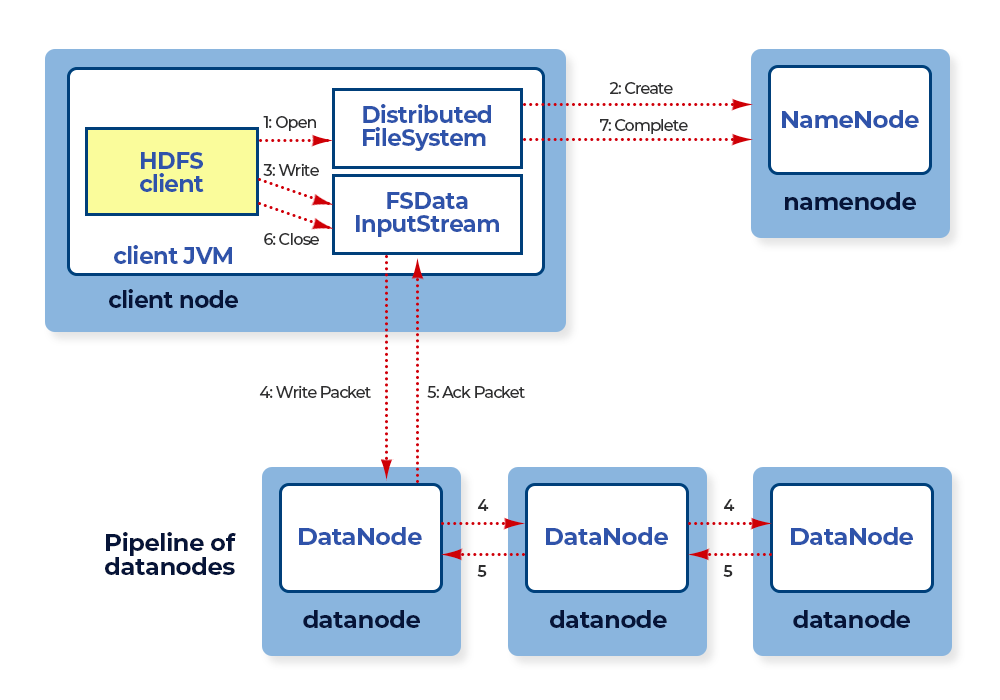
Anatomy of File Write in HDFS
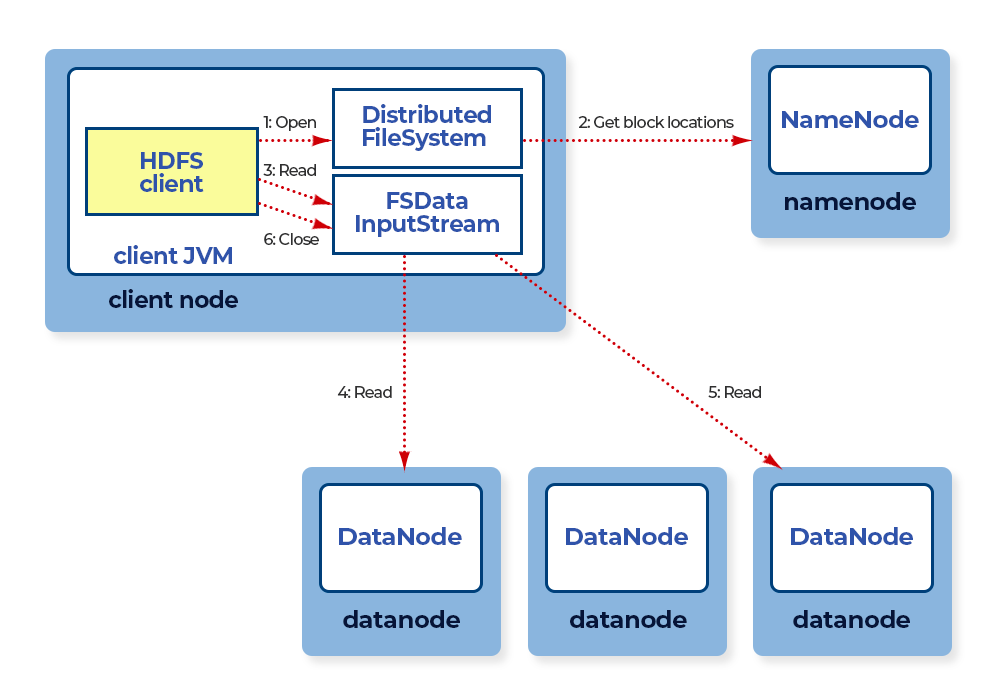
Anatomy of File Read in HDFS
Features of HDFS
- Fault tolerant – HDFS uses mirroring at block level and dfs.replication controls how many copies should be made.
- Traditionally we use RAID for fault tolerance of Hard Drive failures in Network Storage.
- In Hadoop replication takes care of not only Hard Drive failures but also any other hardware failure which might result in server crash or planned maintenance.
- By default if there are m nodes and n is replication factor where m > n, the cluster survive n-1 node failures.
- Logical Distributed File System – The files are divided into blocks based upon the dfs.blocksize and stored in the servers designated as data nodes.
- Rack Awareness
- Replication Factor can cover failure of n-1 nodes for any serious reason at individual server level.
- We use redundant network to cover any network cable related issues.
- However, if there is network switch failure or complete rack failure where servers are hosted – then there will be outage at the cluster level.
- To overcome this we can configure Rack Awareness script. For this servers need to be configured on multiple racks behind 2 network switches.
- We need to come up with strategy and then rack awareness script in such a way that at least one copy will be made in each of the racks in a multi rack Hadoop cluster behind multiple network switches (typically 2 or more).
- We will see how to configure rack awareness script at a later point in time.